12月31日论文解读
Paper Title
- Stable Diffusion

- X-Y plot of algorithmically generated AI art of European style castle in Japan demonstrating DDIM diffusion steps
- The denoising process used by Stable Diffusion. The model generates images by iteratively denoising random noise until a configured number of steps have been reached, guided by the CLIP text encoder pretrained on concepts along with the attention mechanism, resulting in the desired image depicting a representation of the trained concept.
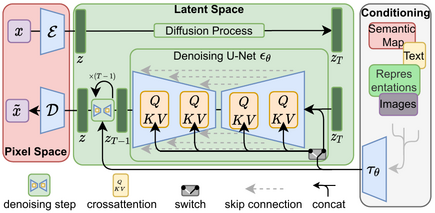
- Stable Diffusion Arch
Intro
Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques. It is considered to be a part of the ongoing AI spring.
It is primarily used to generate detailed images conditioned on text descriptions, though it can also be applied to other tasks such as inpainting, outpainting, and generating image-to-image translations guided by a text prompt. It was developed by researchers from the CompVis Group at Ludwig Maximilian University of Munich and Runway with a compute donation by Stability AI and training data from non-profit organizations.
Stable Diffusion is a latent diffusion model, a kind of deep generative artificial neural network. Its code and model weights have been open sourced, and it can run on most consumer hardware equipped with a modest GPU with at least 4 GB VRAM. This marked a departure from previous proprietary text-to-image models such as DALL-E and Midjourney which were accessible only via cloud services.
Develoment
The development of Stable Diffusion was funded and shaped by the start-up company Stability AI. The technical license for the model was released by the CompVis group at Ludwig Maximilian University of Munich. Development was led by Patrick Esser of Runway and Robin Rombach of CompVis, who were among the researchers who had earlier invented the latent diffusion model architecture used by Stable Diffusion. Stability AI also credited EleutherAI and LAION (a German nonprofit which assembled the dataset on which Stable Diffusion was trained) as supporters of the project.
In October 2022, Stability AI raised US$101 million in a round led by Lightspeed Venture Partners and Coatue Management.
Technology
Architecture
Stable Diffusion uses a kind of diffusion model (DM), called a latent diffusion model (LDM) developed by the CompVis group at LMU Munich. Introduced in 2015, diffusion models are trained with the objective of removing successive applications of Gaussian noise on training images, which can be thought of as a sequence of denoising autoencoders. Stable Diffusion consists of 3 parts: the variational autoencoder (VAE), U-Net, and an optional text encoder. The VAE encoder compresses the image from pixel space to a smaller dimensional latent space, capturing a more fundamental semantic meaning of the image. Gaussian noise is iteratively applied to the compressed latent representation during forward diffusion. The U-Net block, composed of a ResNet backbone, denoises the output from forward diffusion backwards to obtain a latent representation. Finally, the VAE decoder generates the final image by converting the representation back into pixel space.
The denoising step can be flexibly conditioned on a string of text, an image, or another modality. The encoded conditioning data is exposed to denoising U-Nets via a cross-attention mechanism. For conditioning on text, the fixed, pretrained CLIP ViT-L/14 text encoder is used to transform text prompts to an embedding space. Researchers point to increased computational efficiency for training and generation as an advantage of LDMs.
With 860 millions of parameters in the U-Net and 123 millions in the text encoder, Stable Diffusion is considered relatively lightweight by 2022 standards, and unlike other diffusion models, it can run on consumer GPUs.
Training Data
Stable Diffusion was trained on pairs of images and captions taken from LAION-5B, a publicly available dataset derived from Common Crawl data scraped from the web, where 5 billion image-text pairs were classified based on language and filtered into separate datasets by resolution, a predicted likelihood of containing a watermark, and predicted "aesthetic" score (e.g. subjective visual quality). The dataset was created by LAION, a German non-profit which receives funding from Stability AI. The Stable Diffusion model was trained on three subsets of LAION-5B: laion2B-en, laion-high-resolution, and laion-aesthetics v2 5+. A third-party analysis of the model's training data identified that out of a smaller subset of 12 million images taken from the original wider dataset used, approximately 47% of the sample size of images came from 100 different domains, with Pinterest taking up 8.5% of the subset, followed by websites such as WordPress, Blogspot, Flickr, DeviantArt and Wikimedia Commons.[citation needed] An investigation by Bayerischer Rundfunk showed that LAION's datasets, hosted on Hugging Face, contain large amounts of private and sensitive data.
Training Procedures
The model was initially trained on the laion2B-en and laion-high-resolution subsets, with the last few rounds of training done on LAION-Aesthetics v2 5+, a subset of 600 million captioned images which the LAION-Aesthetics Predictor V2 predicted that humans would, on average, give a score of at least 5 out of 10 when asked to rate how much they liked them. The LAION-Aesthetics v2 5+ subset also excluded low-resolution images and images which LAION-5B-WatermarkDetection identified as carrying a watermark with greater than 80% probability. Final rounds of training additionally dropped 10% of text conditioning to improve Classifier-Free Diffusion Guidance.
The model was trained using 256 Nvidia A100 GPUs on Amazon Web Services for a total of 150,000 GPU-hours, at a cost of $600,000.
Limitations
Stable Diffusion has issues with degradation and inaccuracies in certain scenarios. Initial releases of the model were trained on a dataset that consists of 512×512 resolution images, meaning that the quality of generated images noticeably degrades when user specifications deviate from its "expected" 512×512 resolution; the version 2.0 update of the Stable Diffusion model later introduced the ability to natively generate images at 768×768 resolution. Another challenge is in generating human limbs due to poor data quality of limbs in the LAION database. The model is insufficiently trained to understand human limbs and faces due to the lack of representative features in the database, and prompting the model to generate images of such type can confound the model. Stable Diffusion XL (SDXL) version 1.0, released in July 2023, introduced native 1024x1024 resolution and improved generation for limbs and text.
Accessibility for individual developers can also be a problem. In order to customize the model for new use cases that are not included in the dataset, such as generating anime characters ("waifu diffusion"), new data and further training are required. Fine-tuned adaptations of Stable Diffusion created through additional retraining have been used for a variety of different use-cases, from medical imaging to algorithmically generated music. However, this fine-tuning process is sensitive to the quality of new data; low resolution images or different resolutions from the original data can not only fail to learn the new task but degrade the overall performance of the model. Even when the model is additionally trained on high quality images, it is difficult for individuals to run models in consumer electronics. For example, the training process for waifu-diffusion requires a minimum 30 GB of VRAM, which exceeds the usual resource provided in such consumer GPUs as Nvidia's GeForce 30 series, which has only about 12 GB.
The creators of Stable Diffusion acknowledge the potential for algorithmic bias, as the model was primarily trained on images with English descriptions. As a result, generated images reinforce social biases and are from a western perspective, as the creators note that the model lacks data from other communities and cultures. The model gives more accurate results for prompts that are written in English in comparison to those written in other languages, with western or white cultures often being the default representation.
End-user fine-tuning
To address the limitations of the model's initial training, end-users may opt to implement additional training to fine-tune generation outputs to match more specific use-cases, a process also referred to as personalization. There are three methods in which user-accessible fine-tuning can be applied to a Stable Diffusion model checkpoint:
An "embedding" can be trained from a collection of user-provided images, and allows the model to generate visually similar images whenever the name of the embedding is used within a generation prompt. Embeddings are based on the "textual inversion" concept developed by researchers from Tel Aviv University in 2022 with support from Nvidia, where vector representations for specific tokens used by the model's text encoder are linked to new pseudo-words. Embeddings can be used to reduce biases within the original model, or mimic visual styles. A "hypernetwork" is a small pretrained neural network that is applied to various points within a larger neural network, and refers to the technique created by NovelAI developer Kurumuz in 2021, originally intended for text-generation transformer models. Hypernetworks steer results towards a particular direction, allowing Stable Diffusion-based models to imitate the art style of specific artists, even if the artist is not recognised by the original model; they process the image by finding key areas of importance such as hair and eyes, and then patch these areas in secondary latent space. DreamBooth is a deep learning generation model developed by researchers from Google Research and Boston University in 2022 which can fine-tune the model to generate precise, personalised outputs that depict a specific subject, following training via a set of images which depict the subject.
Capabilities
The Stable Diffusion model supports the ability to generate new images from scratch through the use of a text prompt describing elements to be included or omitted from the output. Existing images can be re-drawn by the model to incorporate new elements described by a text prompt (a process known as "guided image synthesis") through its diffusion-denoising mechanism. In addition, the model also allows the use of prompts to partially alter existing images via inpainting and outpainting, when used with an appropriate user interface that supports such features, of which numerous different open source implementations exist.
Stable Diffusion is recommended to be run with 10 GB or more VRAM, however users with less VRAM may opt to load the weights in float16 precision instead of the default float32 to tradeoff model performance with lower VRAM usage.
Text to image generation
The text to image sampling script within Stable Diffusion, known as "txt2img", consumes a text prompt in addition to assorted option parameters covering sampling types, output image dimensions, and seed values. The script outputs an image file based on the model's interpretation of the prompt. Generated images are tagged with an invisible digital watermark to allow users to identify an image as generated by Stable Diffusion, although this watermark loses its efficacy if the image is resized or rotated.
Each txt2img generation will involve a specific seed value which affects the output image. Users may opt to randomize the seed in order to explore different generated outputs, or use the same seed to obtain the same image output as a previously generated image. Users are also able to adjust the number of inference steps for the sampler; a higher value takes a longer duration of time, however a smaller value may result in visual defects. Another configurable option, the classifier-free guidance scale value, allows the user to adjust how closely the output image adheres to the prompt. More experimentative use cases may opt for a lower scale value, while use cases aiming for more specific outputs may use a higher value.
Additional text2img features are provided by front-end implementations of Stable Diffusion, which allow users to modify the weight given to specific parts of the text prompt. Emphasis markers allow users to add or reduce emphasis to keywords by enclosing them with brackets. An alternative method of adjusting weight to parts of the prompt are "negative prompts". Negative prompts are a feature included in some front-end implementations, including Stability AI's own DreamStudio cloud service, and allow the user to specify prompts which the model should avoid during image generation. The specified prompts may be undesirable image features that would otherwise be present within image outputs due to the positive prompts provided by the user, or due to how the model was originally trained, with mangled human hands being a common example.
Image modification
Stable Diffusion also includes another sampling script, "img2img", which consumes a text prompt, path to an existing image, and strength value between 0.0 and 1.0. The script outputs a new image based on the original image that also features elements provided within the text prompt. The strength value denotes the amount of noise added to the output image. A higher strength value produces more variation within the image but may produce an image that is not semantically consistent with the prompt provided.
The ability of img2img to add noise to the original image makes it potentially useful for data anonymization and data augmentation, in which the visual features of image data are changed and anonymized. The same process may also be useful for image upscaling, in which the resolution of an image is increased, with more detail potentially being added to the image. Additionally, Stable Diffusion has been experimented with as a tool for image compression. Compared to JPEG and WebP, the recent methods used for image compression in Stable Diffusion face limitations in preserving small text and faces.
Additional use-cases for image modification via img2img are offered by numerous front-end implementations of the Stable Diffusion model. Inpainting involves selectively modifying a portion of an existing image delineated by a user-provided layer mask, which fills the masked space with newly generated content based on the provided prompt. A dedicated model specifically fine-tuned for inpainting use-cases was created by Stability AI alongside the release of Stable Diffusion 2.0. Conversely, outpainting extends an image beyond its original dimensions, filling the previously empty space with content generated based on the provided prompt.
A depth-guided model, named "depth2img", was introduced with the release of Stable Diffusion 2.0 on November 24, 2022; this model infers the depth of the provided input image, and generates a new output image based on both the text prompt and the depth information, which allows the coherence and depth of the original input image to be maintained in the generated output.
ControlNet
ControlNet is a neural network architecture designed to manage diffusion models by incorporating additional conditions. It duplicates the weights of neural network blocks into a "locked" copy and a "trainable" copy. The "trainable" copy learns the desired condition, while the "locked" copy preserves the original model. This approach ensures that training with small datasets of image pairs does not compromise the integrity of production-ready diffusion models. The "zero convolution" is a 1×1 convolution with both weight and bias initialized to zero. Before training, all zero convolutions produce zero output, preventing any distortion caused by ControlNet. No layer is trained from scratch; the process is still fine-tuning, keeping the original model secure. This method enables training on small-scale or even personal devices.
Releases
- 1.4 August 2022
- 1.5 October 2022
- 2.0 November 2022
- 2.1 December 2022
- XL 1.0 July 2023
Usage and Controversy
Stable Diffusion claims no rights on generated images and freely gives users the rights of usage to any generated images from the model provided that the image content is not illegal or harmful to individuals. This also leads to large amounts of private and sensitive information in the training data.
As visual styles and compositions are not subject to copyright, it is often interpreted that users of Stable Diffusion who generate images of artworks should not be considered to be infringing upon the copyright of visually similar works. However, individuals depicted in generated images may be protected by personality rights if their likeness is used, and intellectual property such as recognizable brand logos still remain protected by copyright. Nonetheless, visual artists have expressed concern that widespread usage of image synthesis software such as Stable Diffusion may eventually lead to human artists, along with photographers, models, cinematographers, and actors, gradually losing commercial viability against AI-based competitors.
Stable Diffusion is notably more permissive in the types of content users may generate, such as violent or sexually explicit imagery, in comparison to other commercial products based on generative AI. Addressing the concerns that the model may be used for abusive purposes, CEO of Stability AI, Emad Mostaque, argues that "[it is] peoples' responsibility as to whether they are ethical, moral, and legal in how they operate this technology", and that putting the capabilities of Stable Diffusion into the hands of the public would result in the technology providing a net benefit, in spite of the potential negative consequences. In addition, Mostaque argues that the intention behind the open availability of Stable Diffusion is to end corporate control and dominance over such technologies, who have previously only developed closed AI systems for image synthesis. This is reflected by the fact that any restrictions Stability AI places on the content that users may generate can easily be bypassed due to the availability of the source code.
Controversy around photorealistic sexualized depictions of underage characters have been brought up, due to such images generated by Stable Diffusion being shared on websites such as Pixiv.
web UI, extensions and more
main Web UI

Extensions
- ADetailer: Used for auto detecting, masking and inpainting with detection model.
- AnimateDiff: Used for turning most community models into animation generators.
- ControlNet: Used for controlling diffusion models.
- Segment Anything: Used for producing high quality object masks from input prompts.
- Inpaint Anything: Used for inpainting anything in images, videos and 3D scenes!
- Openpose Editor: Used for positioning the posture of the human.
Launcher
- 秋叶
More
- COMFYUI启动器铁锅炖