2023-12-10MoE技术解读
Authors
Sophia Yang, Ph.D.
What is Mixture-of-Experts (MoE)?
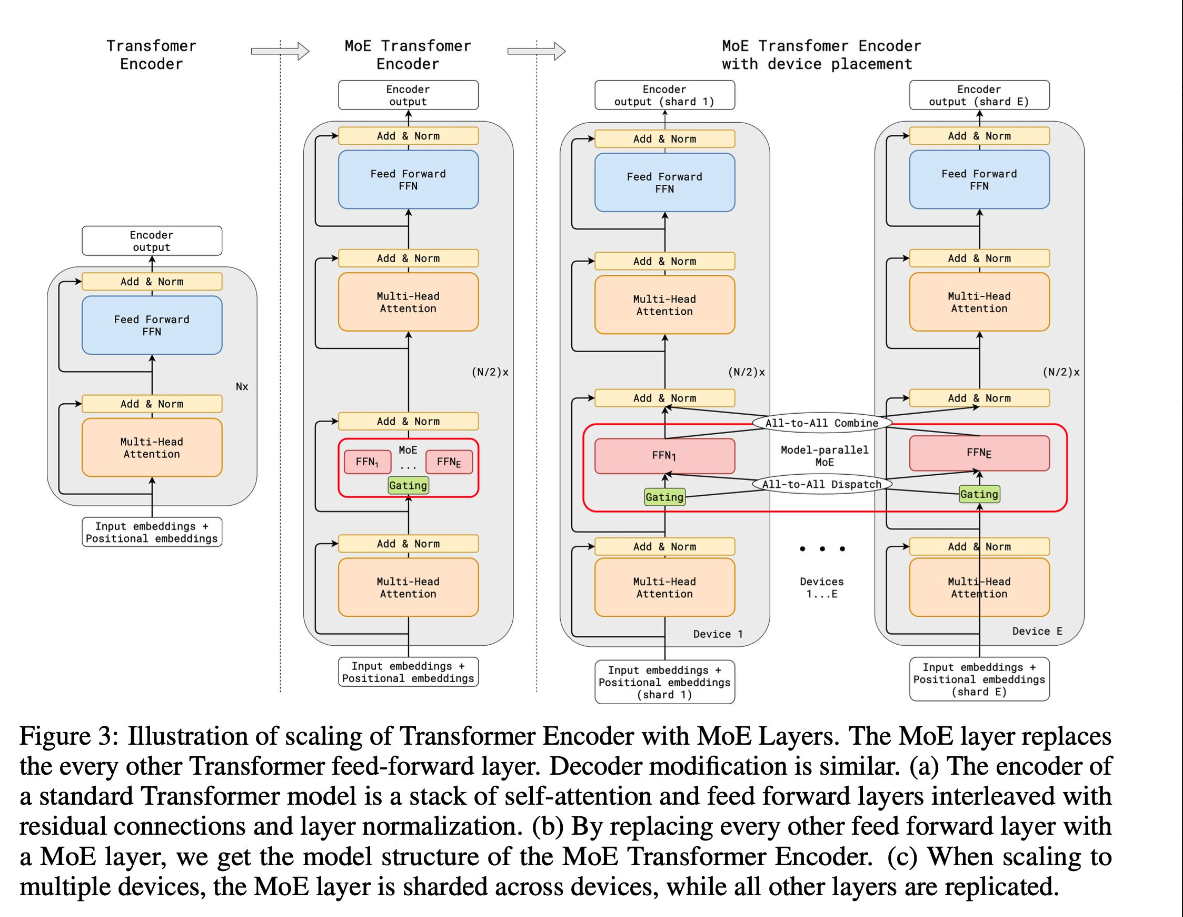
MoE is a neural network architecture design that integrates layers of experts/models within the Transformer block. As data flows through the MoE layers, each input token is dynamically routed to a subset of the experts for computation. This approach allows for more efficient compute with better results as each expert becomes specialized at particular tasks.
Key Components
- Experts: MoE layers comprise many experts, small MLPs or complex LLMs like Mistral 7B.
- Router: Routers determine which input tokens get assigned to which experts. There are two routing strategies: token chooses the router or router chooses the token. How does it work exactly? It uses a softmax gating function to model a probability distribution through experts or tokens and choose the top k.
Why MoE?
- Each expert can be specialized to handle different tasks or different parts of the data.
- Adds learnable parameters to LLMs without increasing inference cost
- Can utilize efficient computation on sparse matrices
- Computes all expert layers in parallel to effectively use the parallel capabilities of GPUs
- Helps scale the model efficiently with reduced training time. Better results at lower computing costs!